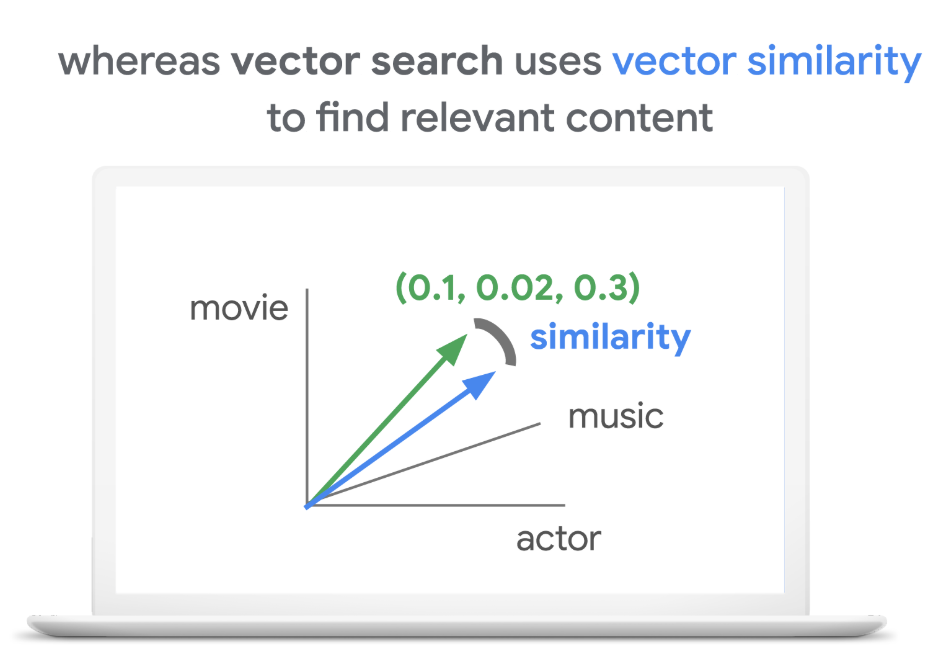
It is ideal for “semantic” search based o similarity. Imaging we store vectorized survey data in DB, we are now able to compute similar feedbacks from users without initiated a python notebook again and again.Given now, BigQuery native support VECTOR_SEARCH[1], now we basically can conduct **Approximate Nearest Neighbor** search directly in BigQuery console, without using python, below is a quick demonstration. Create two tables with `Array` data format storing `embedding values`:
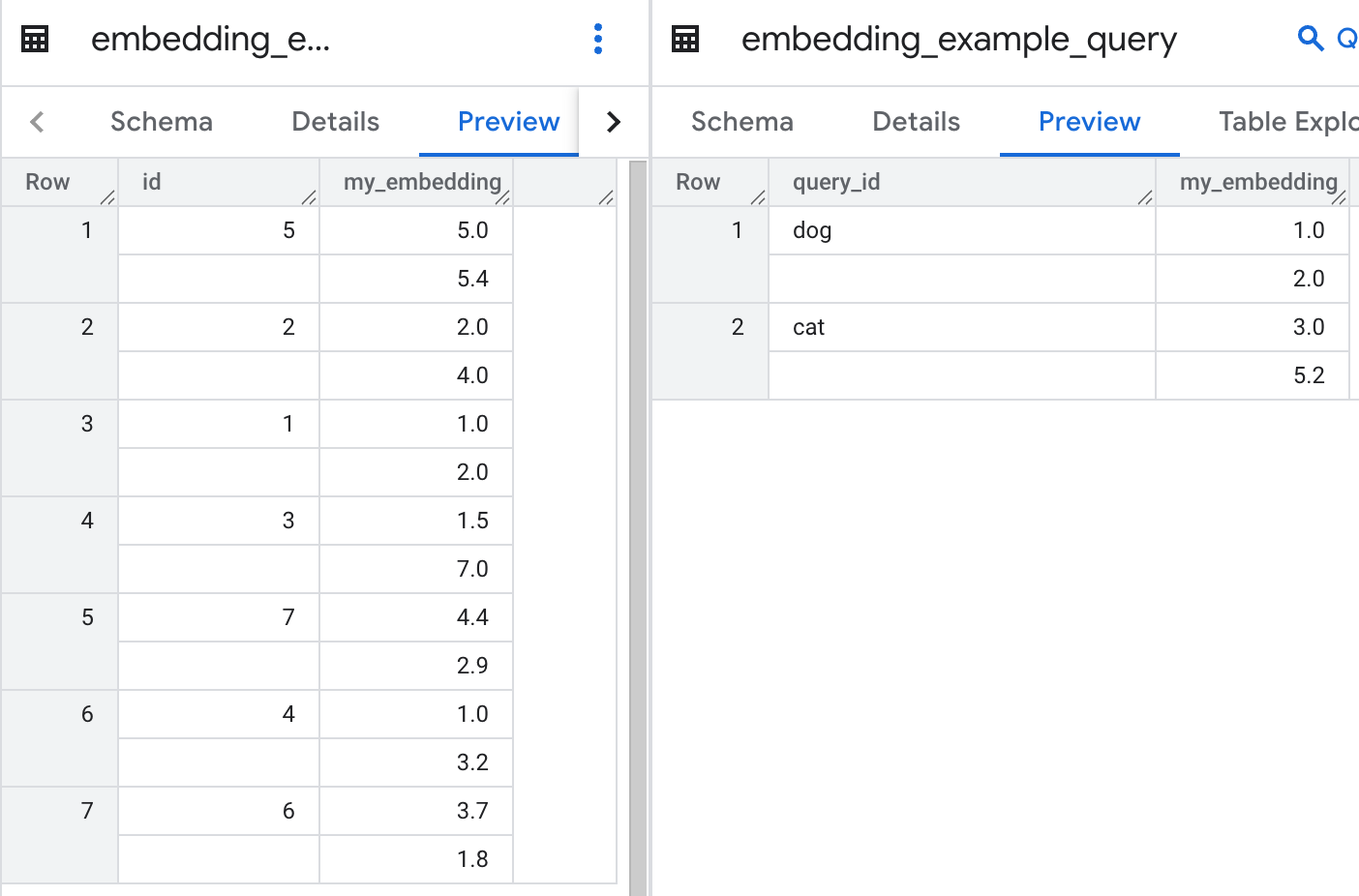
- Create a base table - imaging this table is called Zoo, each vector are different animals
-- random is the dataset name in my GCP project
create or replace table random.embedding_example_base (
id INT64,
my_embedding array<float64>,
);
insert random.embedding_example_base (id, my_embedding)
VALUES(1, [1.0, 2.0]),
(2, [2.0, 4.0]),
(3, [1.5, 7.0]),
(4, [1.0, 3.2]),
(5, [5.0, 5.4]),
(6, [3.7, 1.8]),
(7, [4.4, 2.9]);
- Create a query table - imaging data points in this table is animals you try to find their “similar” species, in this case, you have dog and cat
create or replace table random.embedding_example_query (
query_id STRING,
my_embedding array<float64>,
);
insert random.embedding_example_query (query_id, my_embedding)
VALUES('dog', [1.0, 2.0]),
('cat', [3.0, 5.2]);
 Now, let’s do `VECTOR_SEARCH`
Now, let’s do `VECTOR_SEARCH`
select
*
from vector_search(
table random.embedding_example_base -- base table
, 'my_embedding' -- column to search
, (
select query_id
, my_embedding as query_embedding
from random.embedding_example_query
)
, 'query_embedding'
, top_k => 2
, distance_type => 'COSINE' -- EUCLINDEAN, DOT_PRODUCT
)
- `=>` this is assign symbol
 Then it return following values:
Then it return following values:
- Top 2 most similar **vectors** based on distance values

Final Thoughts
Besides, use BQ as a vector store Db for applications. Now, if a company has ML pipeline (or just BigQuery’s own ML sql)[2] constantly output vectors represent customers behaviors, then now, Data Scientists could directly query those tables and conduct quick similarity analysis without using Python.Vector Search is the new select *BigQuery vector search and embedding generation - YouTube BigQuery as a Vector Database — how cool is that_ _ by Shuvro @ Nimesa _ Medium.pdf